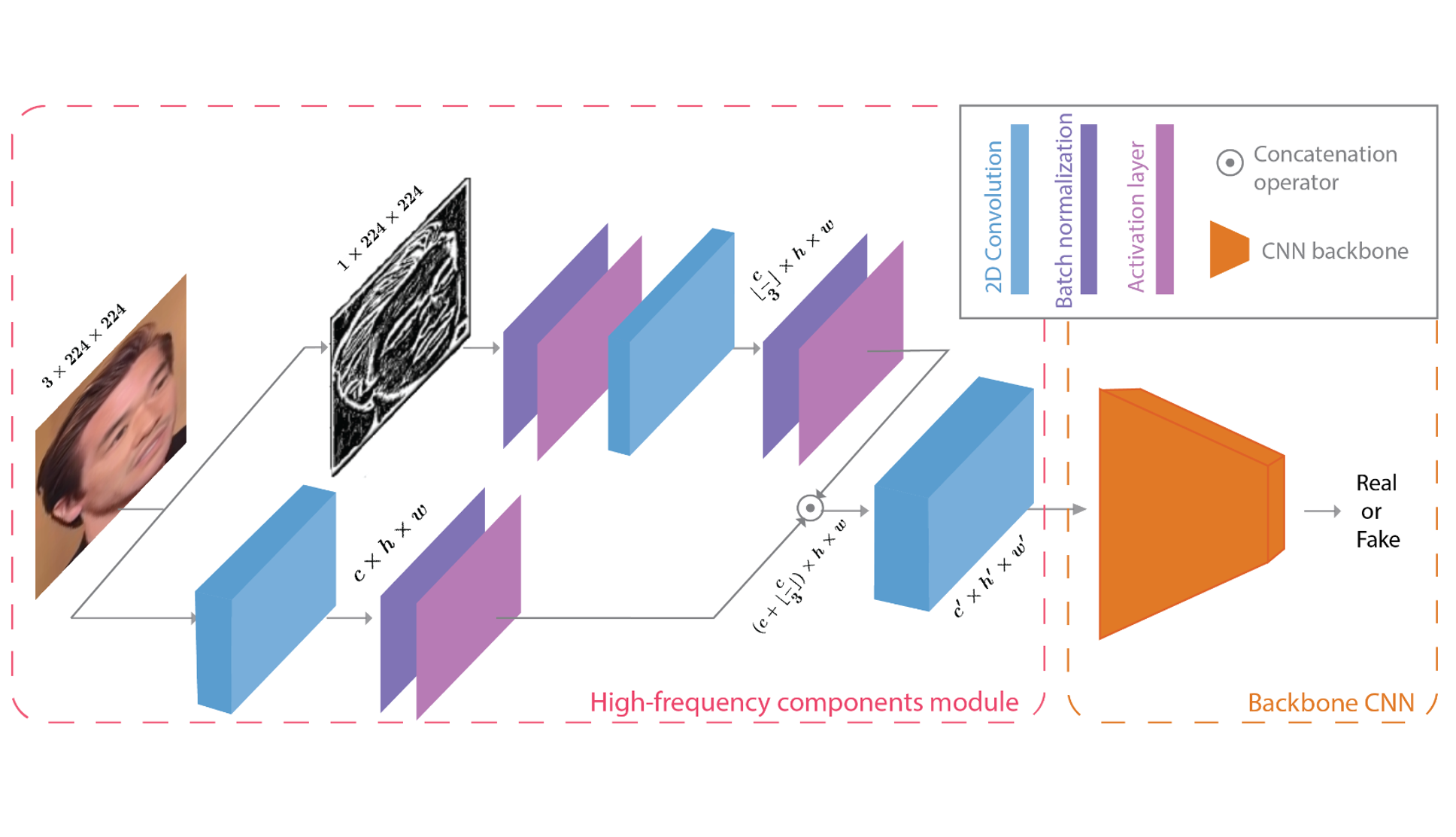
Project description:
With the fast advances in Artificial intelligence, deepfake videos are becoming more accessible and realistic-looking. Their twisted use, constitutes a threat to society Existing deepfake detection methods mostly rely on exploiting discrepancies caused by a given generation method. The goal of FakeDeTeR is to define a more generic approach that captures even deepfakes generated by unknown methods. To that end, discriminative learning-based spatio-temporal-spectral representations are investigated. Leveraging geometric, dynamic, and semantic models as priors will ensure that the smallest relevant deviations are captured. Coupling videos with sound in a cross-modal representation will further empower the proposed solution.
- Starting date: 01/03/2022
- Duration: 36 months + 12
- Funding source: FNR Bridges
- Researchers: Van Dat Nguyen, Dr. Enjie Ghorbel, Dr. Marcella Astrid, Kankana Roy, Prof. Djamila Aouada (PI)
- Partners: POST